
In the information age, the ability to efficiently navigate, analyze, and synthesize vast amounts of data is critical for knowledge discovery and decision-making. As such, there is a growing need for powerful and efficient deep research systems. These systems, empowered by advancements in artificial intelligence, multi-agent architectures, and automated research workflows, offer transformative capabilities for conducting research and generating insights. This guide delves into the design, implementation, and optimization of robust deep research systems capable of handling complex, open-ended research tasks with high levels of accuracy, reliability, and scalability.
Introduction to Deep Research Systems
Defining Deep Research
Deep research involves comprehensive exploratory analysis aimed at generating a thorough understanding of a given topic. This process goes beyond simple fact retrieval or answering specific questions and includes elements such as strategic planning, multi-dimensional analysis, synthesis and insight generation, and iterative refinement. Unlike direct search-based queries that seek specific answers, deep research systems tackle complex topics in a more expansive and iterative manner.
Architectural Principles of Modern Deep Research Systems

To facilitate efficient and effective deep research, modern systems are built on several key principles that differentiate them from conventional information retrieval and search systems:
Intelligent Orchestration: A foundational aspect of these systems is the use of intelligent orchestration, where a central coordination layer, or orchestrator, manages multiple specialized agents. These agents collaborate to achieve a well-defined research objective, with the orchestrator dynamically distributing work based on the research needs and agents’ capabilities.
Parallel Processing: Deep research systems harness the power of parallel processing, where multiple agents can simultaneously gather and analyze information on different facets of the research topic. This approach dramatically accelerates the research process and broadens the scope of the investigation.
Dynamic Adaptation: Adaptive deep research systems can modify their strategies based on initial findings and user feedback, allowing for more nuanced and comprehensive exploration of the topic.
Persistence: Deep research systems, by design, are stateful, meaning they maintain a persistent memory of past actions, findings, and sources. This persistent state is crucial for handling complex, long-running research tasks that involve multiple iterative steps and require continuity over time.
Patterns of Deep Research System Architecture
As the capabilities and sophistication of deep research systems have evolved, four main architectural patterns have emerged, each suited for different use cases and complexity levels:
Monolithic Architecture
The monolithic architecture is characterized by the consolidation of research capabilities into a single, powerful foundation model. In this pattern, the orchestration, data retrieval, and content processing are handled by a single language model.
Key Characteristics:
Centralized Control: Research tasks are directed and executed through one or more large language models.
Integrated Design: Components of the system are tightly integrated, with little external communication or task delegation.
Sequential Workflow: The process flow is linear, with integrated steps for tool use and validation.
High Coherence: Reasoning and knowledge synthesis are highly coherent due to a unified operating context.
Optimal Use Cases: Monolithic systems are most suited for scenarios where rapid prototyping and proof-of-concept (POC) systems are required. They work well in environments with limited customization needs and where simplicity and quick deployment are valued over modular scalability.
Pipeline-Based Architecture
Pipeline-based systems break down the research process into distinct, sequential stages, each designed to perform a specific function, such as query processing, information retrieval, content analysis, and output generation. These pipelines are typically linear, with each stage feeding into the next.
Advantages:
Modularity: Each stage of the pipeline can be independently optimized and maintained.
Reproducibility: The workflows are standardized, which helps in achieving consistent results.
Ease of Maintenance: The separation of concerns in the pipeline architecture simplifies debugging and system updates.
Quality Assurance: Inherent checkpoints in the pipeline allow for systematic validation at each stage.
Limitations: Pipeline-based systems lack flexibility for dynamic research scenarios and cannot easily adjust to unexpected results or evolving research questions.
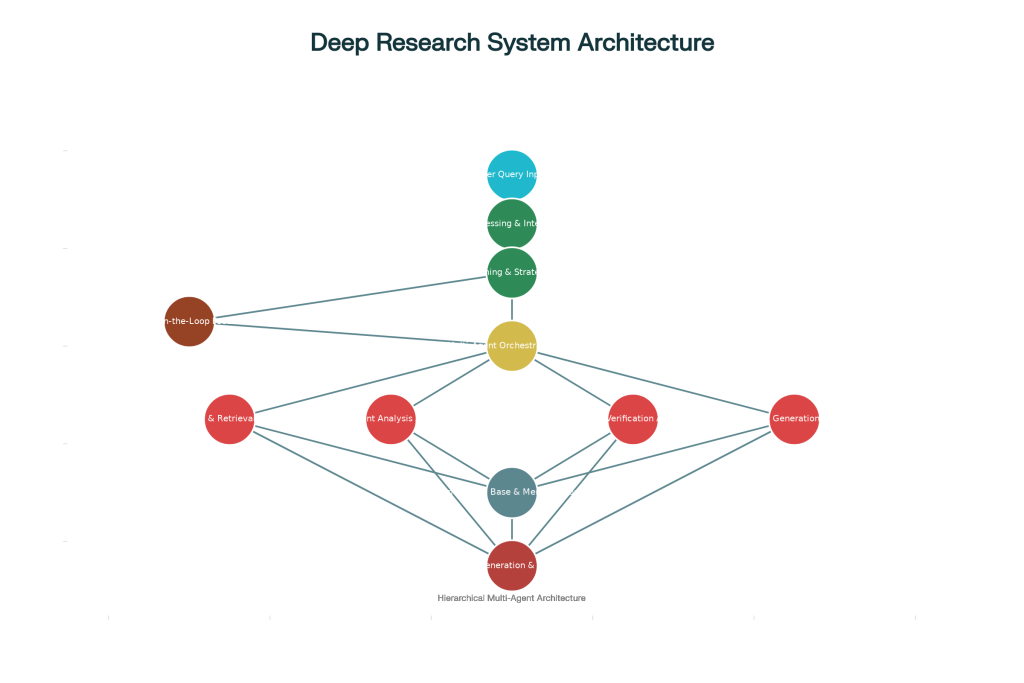
Multi-Agent Architecture
The multi-agent architecture employs a set of specialized autonomous agents that collaborate to perform the research tasks. These agents are orchestrated by a central coordinator and communicate through a shared message bus. They each have dedicated skills and can access specific tools necessary for various research subtasks.
Core Components:
Specialized Agents: These are the individual components that focus on specific aspects such as search, analysis, verification, and synthesis.
Message Bus: A communication layer that facilitates agent coordination and task allocation.
Shared Memory: A collective storage of knowledge that all agents can access and contribute to during the research process.
Dynamic Routing: An intelligent system that routes tasks to the most appropriate agents based on current workload and agent specialization.
Benefits: Multi-agent systems are particularly effective for complex and open-ended research tasks that require varied expertise and adaptive research strategies.
Hybrid Architecture
Hybrid architectures represent the most advanced implementation, dynamically switching between the aforementioned patterns based on the complexity and specific requirements of the research task at hand.
Adaptive Features:
Pattern Recognition: The system can automatically determine the most suitable architecture pattern for a given research query.
Resource Optimization: Balances system performance with research depth and detail.
Scalability: Scales the complexity of the system architecture in response to the demands of the research task.
Extensibility: Designed to incorporate new research methods and emerging technologies.
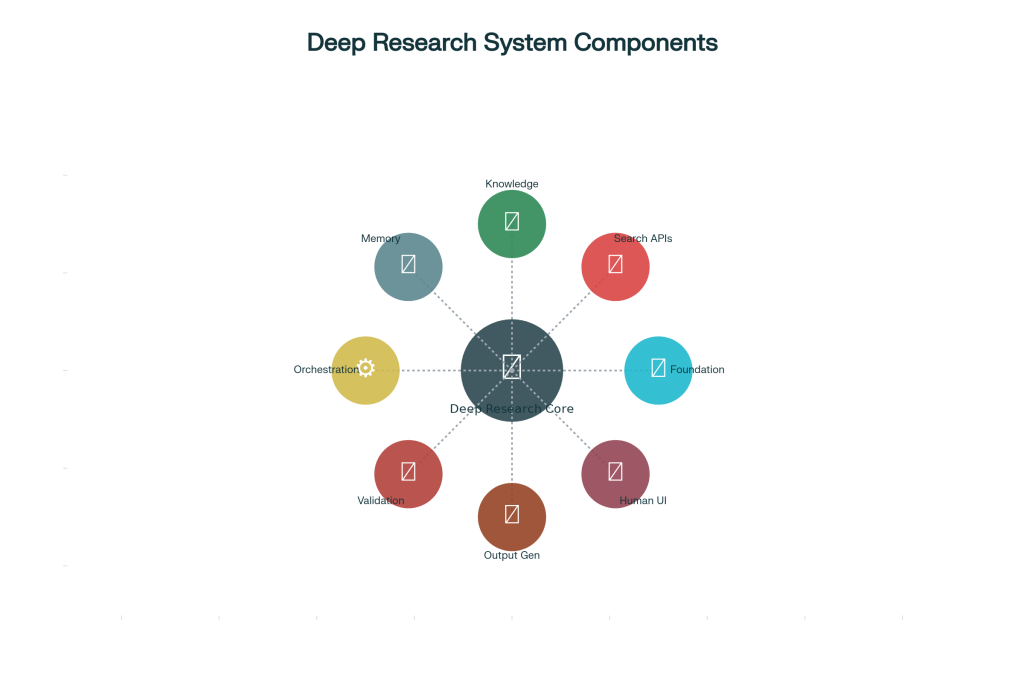
3. Building Blocks of a Powerful Deep Research System
Foundation Models and Reasoning Engines
Foundation models, such as language models with billions of parameters, serve as the core reasoning engines for deep research systems. These models are capable of:
Natural Language Understanding: They can parse and interpret research queries, including understanding implicit requirements and context.
Research Planning: Break down complex research goals into actionable subtasks with a clear sequence and interdependencies.
Knowledge Synthesis: Perform high-level reasoning to find patterns, relationships, and insights across multiple data points.
Iterative Learning: Adapt and refine their approaches based on feedback and the analysis of previous interactions.
Search and Information Retrieval Systems
Effective deep research systems integrate a diverse array of information sources, including search engines, web-based knowledge repositories, academic databases, and proprietary knowledge bases. Advanced systems will also incorporate real-time data feeds and can generate intelligent search queries to explore various aspects of a research topic.
Content Extraction and Processing
Automated extraction tools are utilized to process and extract information from various formats like text documents, images, and videos. These tools are essential for enabling the system to analyze and synthesize information across different media types.
Knowledge Management and Memory
Vector Databases
Vector databases play a crucial role in storing and retrieving information based on semantic similarity. They use embeddings to capture the meaning of data, which allows the system to identify and relate conceptually similar information that may not share exact keywords.
Graph Databases
Graph databases store entities, concepts, and the relationships between them. They support complex queries that can reveal intricate patterns and associations within the knowledge graph.
State Management
Persistent state management is vital for ensuring continuity in long-running or interrupted research processes. This involves storing the research context, intermediate results, and reasoning paths.
4. Quality, Verification, and Validation
Source Verification and Fact Checking
Automated processes for verifying the credibility of sources and the accuracy of information are essential components of a deep research system. This includes checking the authority and relevance of the sources and cross-referencing facts across multiple data points.
Bias Detection and Quality Metrics
Bias detection algorithms assess potential biases in sources and the information itself. Quality metrics are used to evaluate the depth and reliability of the research conducted.
5. Implementation Workflow
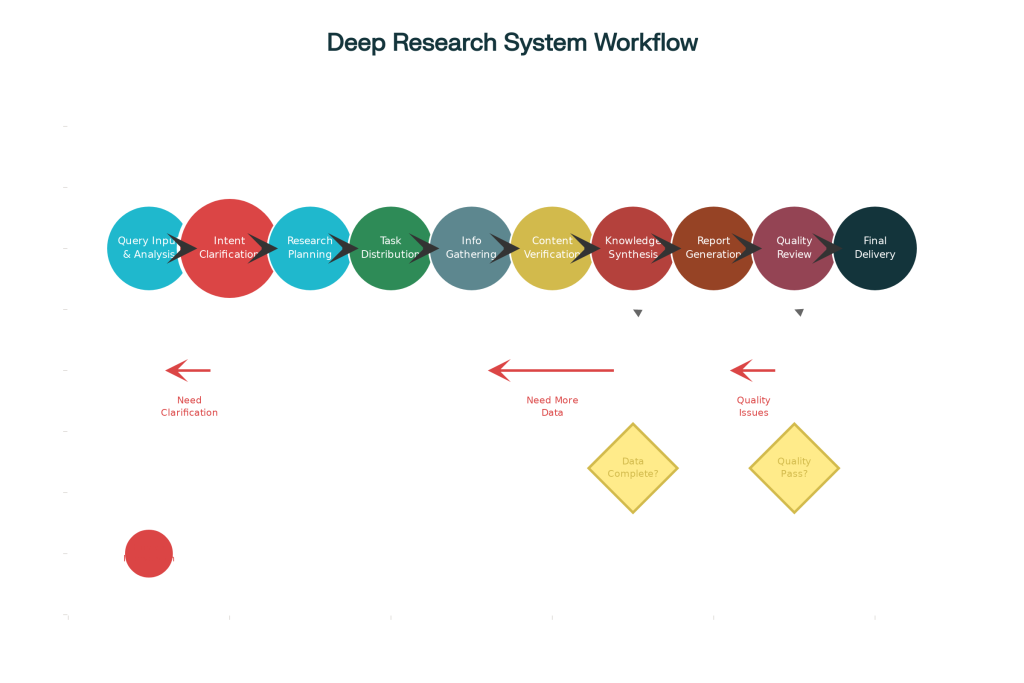
Query Processing and Intent Analysis
The research workflow begins with an in-depth analysis of the research query to ensure a nuanced understanding of the explicit and implicit needs. This includes defining the scope and success criteria for the research.
Research Strategy and Approach
The system will then plan the research strategy, which may be structured as a DAG for better management of task dependencies and parallel execution opportunities.
Orchestrator: Task Distribution to Agents
The orchestrator assigns research tasks to agents based on their capabilities, current workload, and the defined strategy. The system ensures that quality validation is in place for critical tasks.
Information Gathering and Processing by Agents
Agents will carry out the assigned research tasks, gathering and processing information. This may involve parallel execution of tasks to improve efficiency.
Synthesis and Report Generation
The system synthesizes all findings into a coherent response or report, ensuring that insights are clearly linked to the evidence found during the research process.
6. Best Practices and Optimization Strategies
Data Quality and Integrity
Ensuring data quality involves using diverse sources and implementing robust validation pipelines. Best practices include cross-verifying facts, assessing the authority of sources, and detecting and mitigating biases.
Human-AI Collaboration
Designing touchpoints for human oversight and validation is critical. This can include human review of research strategies, quality checkpoints, and final report validations by domain experts.
Scalability and Performance
To ensure scalability, the system should be designed with modularity in mind. This includes independent scaling of components, dynamic resource allocation, and isolated updates and maintenance.
Error Handling and System Robustness
Robust error handling mechanisms are important to ensure the system can gracefully handle and recover from failures. This includes implementing retry logic, alternative workflows, and comprehensive error logging.
7. Advanced Features and Optimization
Incorporating AI-Enhanced Capabilities
AI features such as machine learning for predictive analytics, pattern recognition, and natural language generation can significantly enhance the capabilities of a deep research system.
Real-Time Information Processing
Systems should be optimized to handle real-time information, which can be crucial for time-sensitive research tasks. This includes processing live data feeds and adapting research strategies based on new information.
Visualization and Presentation Tools
Advanced output generation features, including interactive visualizations and multi-format support, can greatly improve the accessibility and utility of research findings.
8. Future Directions and Trends
Integration with Specialized Domains
Future systems are likely to become more specialized, integrating with domain-specific systems and databases such as scientific research platforms, business intelligence tools, legal research databases, and medical research repositories.
Leveraging Advanced AI Capabilities
As AI technologies advance, new capabilities such as multimodal content analysis, causal reasoning, temporal analysis, and uncertainty quantification will become integral to deep research systems.
Building Collaborative Research Networks
The future also points towards distributed research ecosystems that enable secure sharing of research findings and collective intelligence across organizations and systems.
Conclusion
Deep research systems, empowered by AI and multi-agent architectures, are transforming the research landscape by enabling more powerful and efficient knowledge discovery. The design and implementation of these systems must be carefully considered, with a focus on architectural patterns, component integration, and operational best practices. As AI and information volumes continue to grow, deep research systems will become increasingly vital for organizations looking to gain a competitive edge through advanced research capabilities.
About the Author
Andy Obumneme Abasili is a seasoned technology executive and researcher with a track record in AI/ML implementation, and cloud architecture. With a Ph. D, DBA, and MBA, complemented by professional certifications such as CCA™, Dr Andy Abasili has a strong foundation in both academic research and practical application in the field of technology and information services.
As the founder of Jabez Grace CloudTech Solutions Ltd, Dr Andy Abasili is at the forefront of guiding organizations in the adoption of emerging technologies to enhance their research and knowledge discovery processes. With a portfolio that includes AI/ML technologies, cloud solutions, and intelligent automation, his expertise spans across developing and implementing systems that drive digital transformation.
For further inquiries or consulting on deep research systems, Dr Andy Obumneme Abasili can be reached at andyabasili@jabezgrace.com.
3 comments
https://shorturl.fm/RcBgd
https://shorturl.fm/ppR0s
https://shorturl.fm/XEEal